
Random Test Data Generator Tutorial Part 3: Master Export Formats and Professional Workflows
Complete guide to exporting test data in JSON, CSV, SQL, and XML formats. Learn professional workflows, batch processing, and integration strategies.
Random Test Data Generator Tutorial Part 3: Advanced Export Features and Professional Workflows
Welcome to the another part of our Random Test Data Generator tutorial series! In this comprehensive guide, we'll explore advanced export features, format customization, and professional workflows that will transform how you handle test data.
Prerequisites
- Understanding of database concepts and file formats
- Basic knowledge of SQL and data import processes
Objectives
By the end of Part 3, you'll be expert at:
- Customizing export formats for specific needs
- Implementing professional data generation workflows
- Optimizing performance for large datasets
- Integrating generated data into development pipelines
- Troubleshooting common export issues
Step 1: JSON Export Mastery
Array vs Object Structure
Array Structure (Default):
[
{"id": 1, "name": "John", "email": "[email protected]"},
{"id": 2, "name": "Jane", "email": "[email protected]"}
]
Object Structure (Key-Value Pairs):
{
"record_1": {"id": 1, "name": "John", "email": "[email protected]"},
"record_2": {"id": 2, "name": "Jane", "email": "[email protected]"}
}
When to Use Each Format
- Array: REST APIs, JavaScript applications, most data processing
- Object: Configuration files, lookup tables, keyed data access
Professional JSON Workflows
Step 2: CSV Export Optimization
Delimiter Options
- Comma (,): Standard CSV format for Excel, Google Sheets
- Semicolon (;): European Excel standard
- Pipe (|): Database imports, avoids comma conflicts
- Tab: TSV format for specific database systems
CSV Best Practices
- Use semicolon delimiters for European users
- Pipe delimiters for data containing commas
- Always include headers for clarity
- Quote text fields to handle special characters
Example: E-commerce Product CSV
id,name,price,category,description
"PROD001","Gaming Laptop","1299.99","Electronics","High-performance laptop for gaming"
"PROD002","Office Chair","299.50","Furniture","Ergonomic office chair with lumbar support"
Step 3: SQL Export for Database Integration
Customizable Options
- Table Name: Default "fake_data", customize as needed
- Column Types: Automatically set to VARCHAR(255)
- Insert Statements: Batch or individual inserts
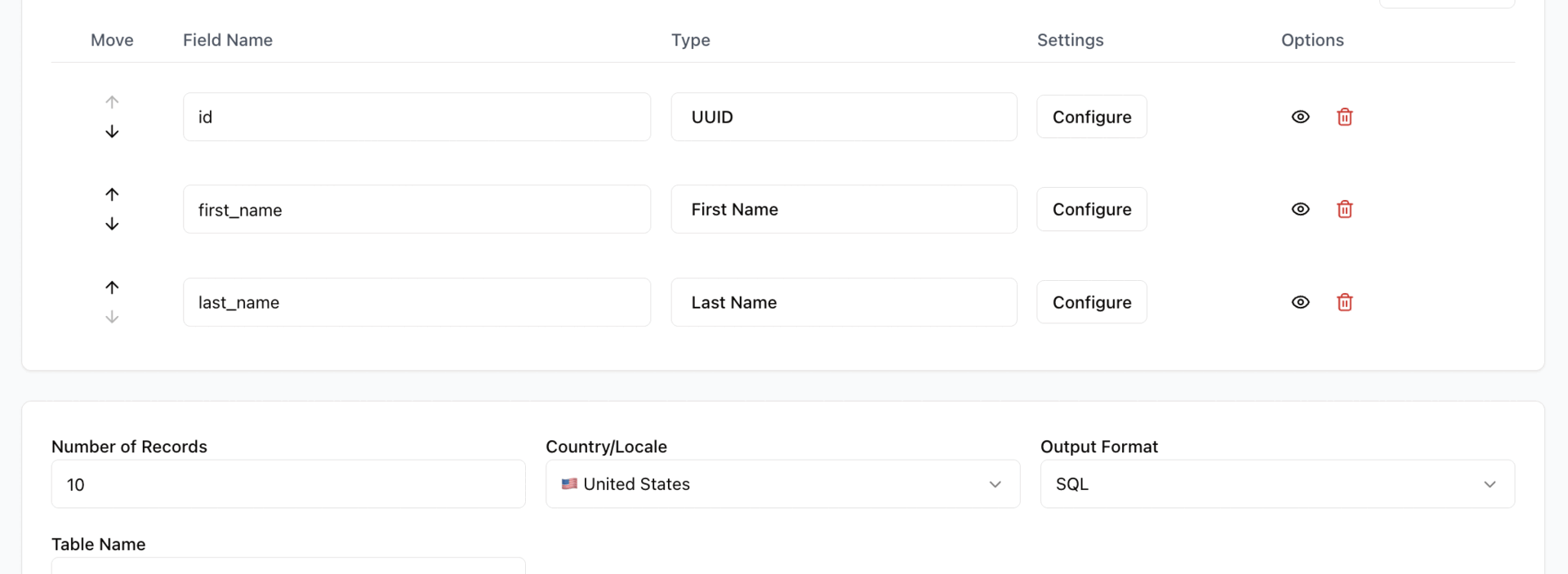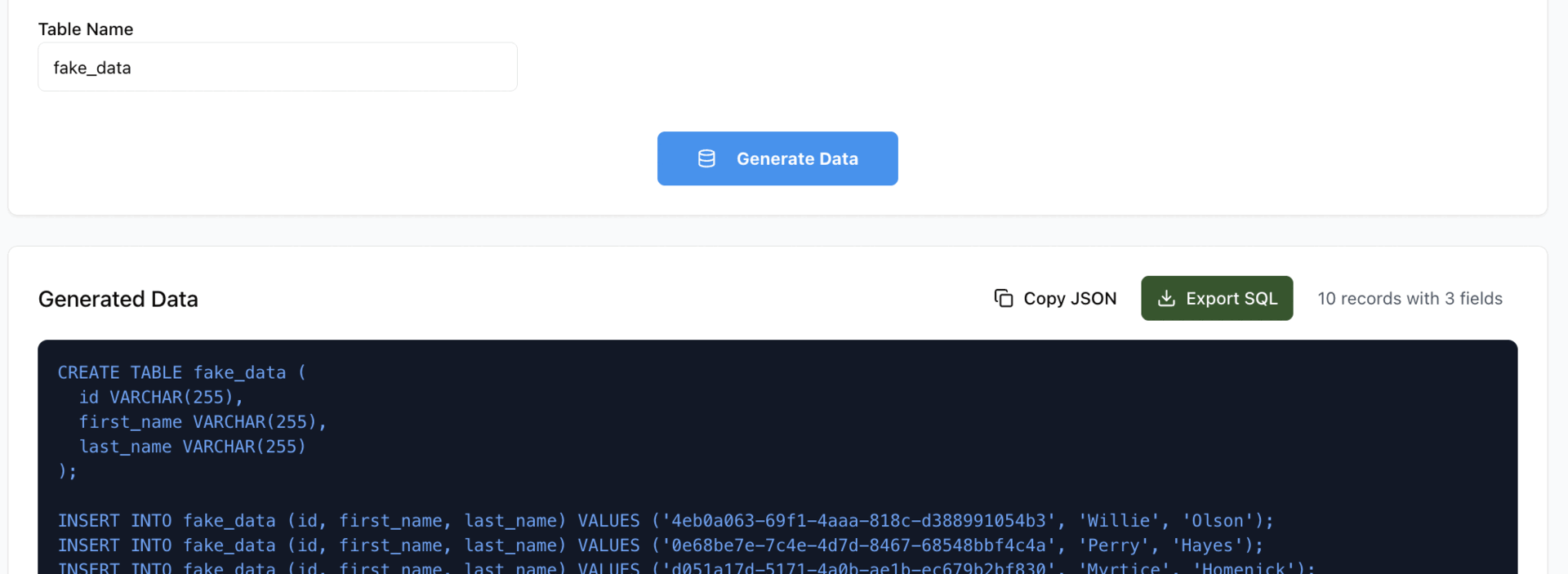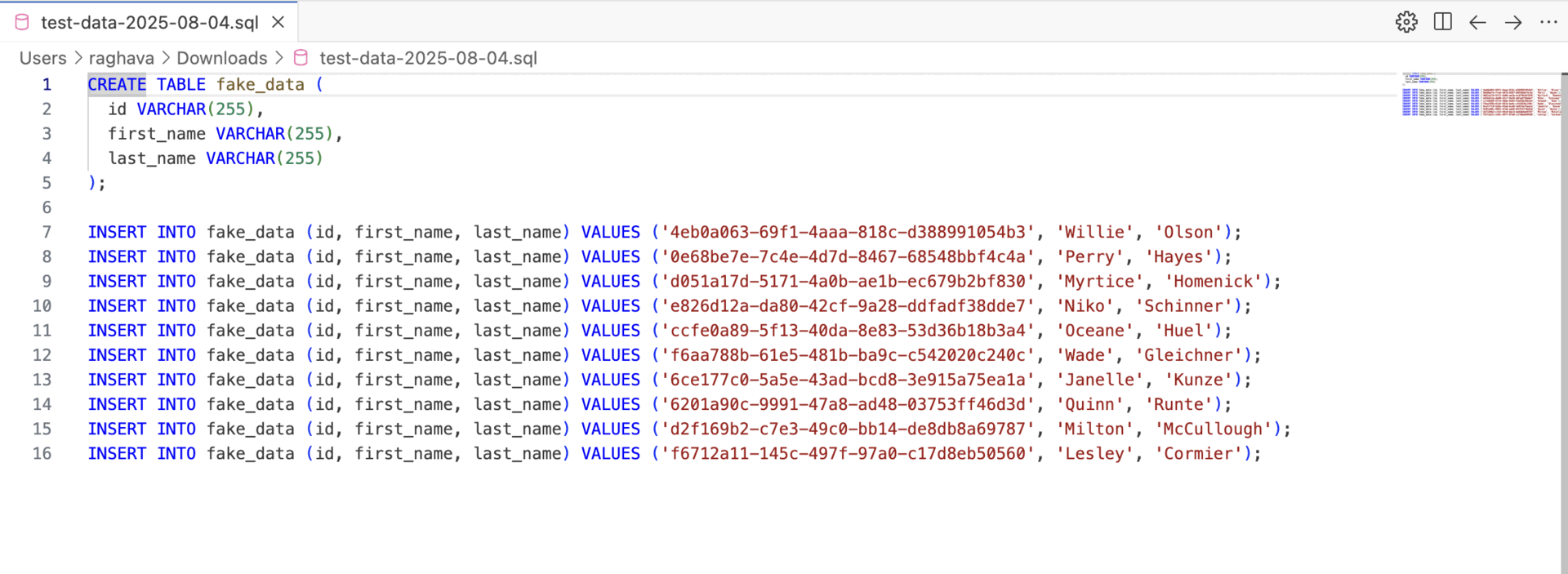
SQL Export Structure
-- Table Creation
CREATE TABLE employees (
id VARCHAR(255),
first_name VARCHAR(255),
last_name VARCHAR(255),
email VARCHAR(255),
department VARCHAR(255),
salary VARCHAR(255)
);-- Data Insertion
INSERT INTO employees (id, first_name, last_name, email, department, salary)
VALUES ('emp_001', 'John', 'Smith', '[email protected]', 'Engineering', '75000');
!SQL export with custom table name
{kind=link}
Database Integration Workflows
Production Considerations
- Review data types after import (convert VARCHAR to appropriate types)
- Add primary keys and constraints after data loading
- Consider batch size for large datasets (500 record limit per generation)
Step 4: XML Export for Legacy Systems
Customizable XML Structure
- Root Tag: Container element (default: "records")
- Record Tag: Individual record element (default: "record")
Example XML Output
emp_001
John
Smith
[email protected]
emp_002
Jane
Doe
[email protected]
XML Use Cases
- Legacy System Integration: SOAP services, older enterprise systems
- Configuration Files: Application settings, deployment configs
- Data Exchange: B2B integrations, EDI systems
- Testing: XML parsing and validation testing
Step 5: Performance Optimization Strategies
Record Limits and Batching
- Single Generation: Up to 500 records maximum
- Large Datasets: Generate multiple batches
- Memory Management: Browser handles processing efficiently
Batch Generation Workflow
Field Optimization
- Minimize Complex Fields: DNA sequences, long text fields impact performance
- Optimize Constraints: Simpler constraints generate faster
- Reduce Field Count: Fewer fields = faster generation
Step 6: Professional Integration Workflows
Contact us at contact[at]qelab[dot]org to get access to the API to generate data for integration workflows.
Continuous Integration (CI) Pipeline
Example: Automated test data generation script
curl -X POST https://api.qelab.org/generate-data \
-H "Content-Type: application/json" \
-d '{"count": 100, "format": "json", "fields": [...]}' \
> test-data.json
Development Environment Setup
Version Control Considerations
- Commit Generated Data: Include test datasets in repository
- Data Versioning: Tag datasets with specific test scenarios
- Documentation: Document field configurations for reproducibility
Step 7: Advanced Use Cases
A/B Testing Data Generation
Generate datasets for testing different scenarios:
- User Cohorts: Different demographic profiles
- Product Variations: Multiple product categories
- Geographic Distribution: Various locale-based datasets
Load Testing Scenarios
- User Registration: Realistic user signup data
- Transaction Processing: Financial transaction datasets
- Content Management: Articles, comments, user-generated content
Data Privacy Compliance
- GDPR Compliance: No real personal data involved
- Testing Anonymization: Practice data anonymization techniques
- Synthetic Data Benefits: Avoid privacy concerns with realistic fake data
Step 8: Troubleshooting Common Issues
Export Failures
- Large Datasets: Break into smaller batches
- Complex Constraints: Simplify field configurations
- Browser Memory: Refresh page for memory cleanup
Format-Specific Issues
- CSV: Character encoding problems → Use UTF-8
- SQL: Special characters in data → Proper escaping applied automatically
- XML: Invalid characters → Tool handles XML encoding
- JSON: Large numbers → Consider string formatting for precision
Data Quality Issues
- Inconsistent Locales: Ensure locale settings match requirements
- Unrealistic Constraints: Review min/max values for realism
- Field Relationships: Tool generates independent fields (no relational constraints)
Professional Tips and Best Practices
Field Naming Conventions
- Use consistent naming (snake_case, camelCase)
- Meaningful field names for clarity
- Avoid reserved keywords for SQL exports
Data Consistency
- Use UUIDs for unique identifiers
- Apply consistent date ranges across related fields
- Maintain logical relationships between fields
Documentation Strategy
- Document field configurations for team use
- Create templates for common scenarios
- Version control configuration documentation
Real-World Project Example
Let's create a comprehensive e-commerce dataset:
Required Fields:
Summary
In this comprehensive 3-part series, you've mastered:
Part 1: Basic data generation and interface navigation
Part 2: Advanced field configuration and customization
Part 3: Professional export workflows and integration strategies
Key Takeaways
- The Random Test Data Generator is a professional-grade tool for realistic test data
- Proper field configuration creates more useful datasets
- Export format selection depends on your integration needs
- Performance optimization enables handling large dataset requirements
- Professional workflows integrate seamlessly with development processes
Next Steps
Final Challenge
Create a complete testing dataset for a social media application including:
- User profiles with realistic data
- Posts with engagement metrics
- Comments and interactions
- Analytics data points
Ready to become a test data generation expert? Start building your professional dataset now!
---